1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| # -*-coding:gb2312-*-
import requests
from bs4 import BeautifulSoup
import requests
f = open('./out.txt', 'a')
def spider(id):
burp0_url = "http://192.168.100.212:80/sushe/?t=1536643303"
burp0_cookies = {"PHPSESSID": "ks2d8fdo26hgu7m97089buv8n0"}
burp0_headers = {"User-Agent": "daolgts", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5", "Referer": "http://192.168.100.212/sushe/", "Connection": "close", "Content-Type": "application/x-www-form-urlencoded"}
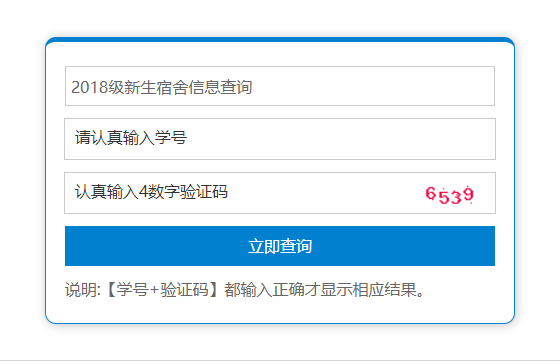
burp0_data = {"time": "2018\xbc\xb6\xd0\xc2\xc9\xfa\xcb\xde\xc9\xe1\xd0\xc5\xcf\xa2\xb2\xe9\xd1\xaf",
"name": id, "code": "2676", "button": "\xc1\xa2\xbc\xb4\xb2\xe9\xd1\xaf"}
r = requests.post(burp0_url, headers=burp0_headers,
cookies=burp0_cookies, data=burp0_data)
r.encoding = 'gb2312'
if '\xc3\xbb\xd3\xd0\xb2\xe9\xd1\xaf\xb5\xbd' in r.text:
return False
soup = BeautifulSoup(r.text, features="html.parser")
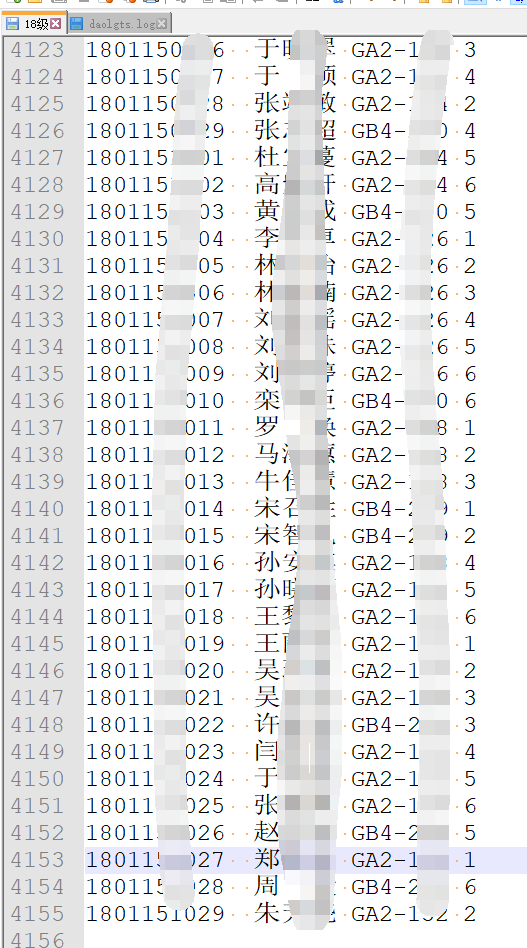
text = soup.find_all('tr', limit=2)[1]
text = str(text).replace("<tr><td>", '').replace(
"</td><td>", '\t').replace("</td></tr>", '') + '\n'
return text
for z in range(1,50):
for y in range(16, 50):
for b in range(1, 20):
for i in range(1, 41):
id = '18'+ str(z).zfill(2) + str(y).zfill(2) + \
str(b).zfill(2) + str(i).zfill(2)
print id
text = spider(id)
if text == False:
break
print "yes"
f.write(text)
|